You Collect Blood Pressure Readings From 150 Patients. What Type of Data Is This?
Sample Statistics
In order to illustrate the ciphering of sample statistics, we selected a small subset (due north=10) of participants in the Framingham Heart Study. The data values for these ten individuals are shown in the tabular array below. The rightmost column contains the body mass index (BMI) computed using the top and weight measurements. Nosotros will come back to this example in the module on Summarizing Data, just it provides a useful analogy of some of the terms that have been introduced and will also serve to illustrate the computation of some sample statistics.
computed using the top and weight measurements. Nosotros will come back to this example in the module on Summarizing Data, just it provides a useful analogy of some of the terms that have been introduced and will also serve to illustrate the computation of some sample statistics.
Information Values for a Small Sample
| Participant ID | Systolic Blood Pressure | Diastolic Blood Pressure | Full Serum Cholesterol | Weight | Elevation | Body Mass Index |
|---|---|---|---|---|---|---|
| one | 141 | 76 | 199 | 138 | 63.00 | 24.iv |
| two | 119 | 64 | 150 | 183 | 69.75 | 26.4 |
| iii | 122 | 62 | 227 | 153 | 65.75 | 24.9 |
| 4 | 127 | 81 | 227 | 178 | 70.00 | 25.5 |
| 5 | 125 | 70 | 163 | 161 | 70.50 | 22.8 |
| 6 | 123 | 72 | 210 | 206 | 70.00 | 29.half-dozen |
| 7 | 105 | 81 | 205 | 235 | 72.00 | 31.9 |
| 8 | 113 | 63 | 275 | 151 | 60.75 | 28.8 |
| 9 | 106 | 67 | 208 | 213 | 69.00 | 31.5 |
| ten | 131 | 77 | 159 | 142 | 61.00 | 26.viii |
The commencement summary statistic that is important to report is the sample size. In this example the sample size is north=10. Considering this sample is small (n=10), it is like shooting fish in a barrel to summarize the sample by inspecting the observed values, for example, by listing the diastolic claret pressures in ascending order:
62 63 64 67 70 72 76 77 81 81
Simple inspection of this modest sample gives us a sense of the center of the observed diastolic pressures and likewise gives us a sense of how much variability there is. However, for a large sample, inspection of the individual data values does non provide a meaningful summary, and summary statistics are necessary. The two cardinal components of a useful summary for a continuous variable are:
- a description of the centre or 'average' of the data (i.e., what is a typical value?) and
- an indication of the variability in the data.
Sample Hateful
At that place are several statistics that describe the center of the data, but for now we volition focus on the sample mean, which is computed by summing all of the values for a particular variable in the sample and dividing past the sample size. For the sample of diastolic blood pressures in the table in a higher place, the sample mean is computed equally follows:
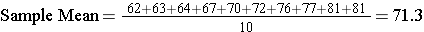
To simplify the formulas for sample statistics (and for population parameters), we normally denote the variable of interest as "Ten". X is just a placeholder for the variable beingness analyzed. Here X=diastolic claret pressure.
The general formula for the sample mean is:
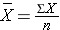
The Ten with the bar over it represents the sample mean, and it is read every bit "X bar". The Σ indicates summation (i.e., sum of the 10's or sum of the diastolic blood pressures in this example).
When reporting summary statistics for a continuous variable, the convention is to report one more decimal place than the number of decimal places measured. Systolic and diastolic blood pressures, full serum cholesterol and weight were measured to the nearest integer, therefore the summary statistics are reported to the nearest tenth place. Height was measured to the nearest quarter inch (hundredths place), therefore the summary statistics are reported to the nearest thousandths place. Body mass index was computed to the nearest tenths place, summary statistics are reported to the nearest hundredths place.
Sample Variance and Standard Departure
If at that place are no extreme or outlying values of the variable, the hateful is the most advisable summary of a typical value, and to summarize variability in the data we specifically gauge the variability in the sample around the sample hateful. If all of the observed values in a sample are close to the sample mean, the standard deviation will be small (i.due east., close to nil), and if the observed values vary widely around the sample hateful, the standard deviation will be large. If all of the values in the sample are identical, the sample standard difference will be goose egg.
When discussing the sample mean, we found that the sample mean for diastolic blood pressure = 71.3. The table below shows each of the observed values along with its respective departure from the sample mean.
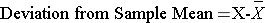
Tabular array - Diastolic Blood Pressures and Deviations from the Sample Mean
| 10=Diastolic Blood Pressure level | Deviation from the Mean |
|---|---|
| 76 | 4.7 |
| 64 | -vii.3 |
| 62 | -9.3 |
| 81 | 9.seven |
| seventy | -1.three |
| 72 | 0.7 |
| 81 | 9.7 |
| 63 | -8.3 |
| 67 | -4.3 |
| 77 | five.7 |
| | |
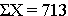
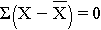
The deviations from the mean reverberate how far each individual's diastolic blood pressure level is from the hateful diastolic blood pressure. The beginning participant's diastolic blood force per unit area is 4.7 units in a higher place the hateful while the second participant's diastolic blood pressure is vii.3 units beneath the hateful. What we demand is a summary of these deviations from the mean, in particular a measure of how far, on average, each participant is from the mean diastolic blood force per unit area. If we compute the mean of the deviations by summing the deviations and dividing by the sample size we come across a trouble. The sum of the deviations from the hateful is zero. This will always exist the case as it is a holding of the sample mean, i.e., the sum of the deviations below the mean will ever equal the sum of the deviations above the hateful. Nevertheless, the goal is to capture the magnitude of these deviations in a summary measure out. To address this trouble of the deviations summing to zero, we could take absolute values or square each deviation from the mean. Both methods would address the problem. The more than popular method to summarize the deviations from the hateful involves squaring the deviations (absolute values are difficult in mathematical proofs). The tabular array below displays each of the observed values, the respective deviations from the sample hateful and the squared deviations from the mean.
| X=Diastolic Claret Pressure level | Difference from the Mean | Squared Deviation from the Mean |
| 76 | four.7 | 22.09 |
| 64 | -7.three | 53.29 |
| 62 | -9.3 | 86.49 |
| 81 | 9.vii | 94.09 |
| lxx | -1.three | 1.69 |
| 72 | 0.7 | 0.49 |
| 81 | 9.7 | 94.09 |
| 63 | -eight.3 | 68.89 |
| 67 | -4.3 | 18.49 |
| 77 | v.7 | 32.49 |
| | | |
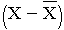
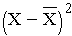
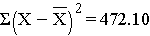
The squared deviations are interpreted equally follows. The commencement participant's squared departure is 22.09 meaning that his/her diastolic blood pressure is 22.09 units squared from the mean diastolic blood pressure, and the 2d participant's diastolic claret pressure is 53.29 units squared from the mean diastolic blood pressure level. A quantity that is often used to mensurate variability in a sample is called the sample variance, and information technology is essentially the mean of the squared deviations. The sample variance is denoted s2 and is computed equally follows:
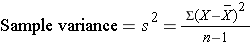
Why do we divided by (north-1) instead of due north?
The sample variance is non actually the mean of the squared deviations, because we dissever past (northward-1) instead of northward. In statistical inference (described in detail in another module) we make generalizations or estimates of population parameters based on sample statistics. If we were to compute the sample variance by taking the mean of the squared deviations and dividing by north we would consistently underestimate the true population variance. Dividing by (n-1) produces a better estimate of the population variance. The sample variance is withal usually interpreted every bit the boilerplate squared deviation from the hateful.
In this sample of northward=10 diastolic blood pressures, the sample variance is s2 = 472.10/9 = 52.46. Thus, on average diastolic blood pressures are 52.46 units squared from the mean diastolic claret pressure level. Considering of the squaring, the variance is non particularly interpretable. The more common measure out of variability in a sample is the sample standard deviation, defined every bit the square root of the sample variance:
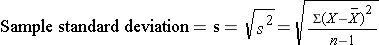
A sample of 10 women seeking prenatal care at Boston Medical center agree to participate in a study to assess the quality of prenatal care. At the time of report enrollment, yous the study coordinator, collected background characteristics on each of the moms including their age (in years).The data are shown beneath:
24 18 28 32 26 21 22 43 27 29


A sample of 12 men have been recruited into a study on the risk factors for cardiovascular disease. The post-obit data are HDL cholesterol levels (mg/dL) at study enrollment:
50 45 67 82 44 51 64 105 56 60 74 68
Source: https://sphweb.bumc.bu.edu/otlt/MPH-Modules/BS/BS704_BiostatisticsBasics/BS704_BiostatisticsBasics3.html
0 Response to "You Collect Blood Pressure Readings From 150 Patients. What Type of Data Is This?"
Post a Comment